清华大学发布大模型综合性能评估报告:文心一言排名第二,通义千问排名第六
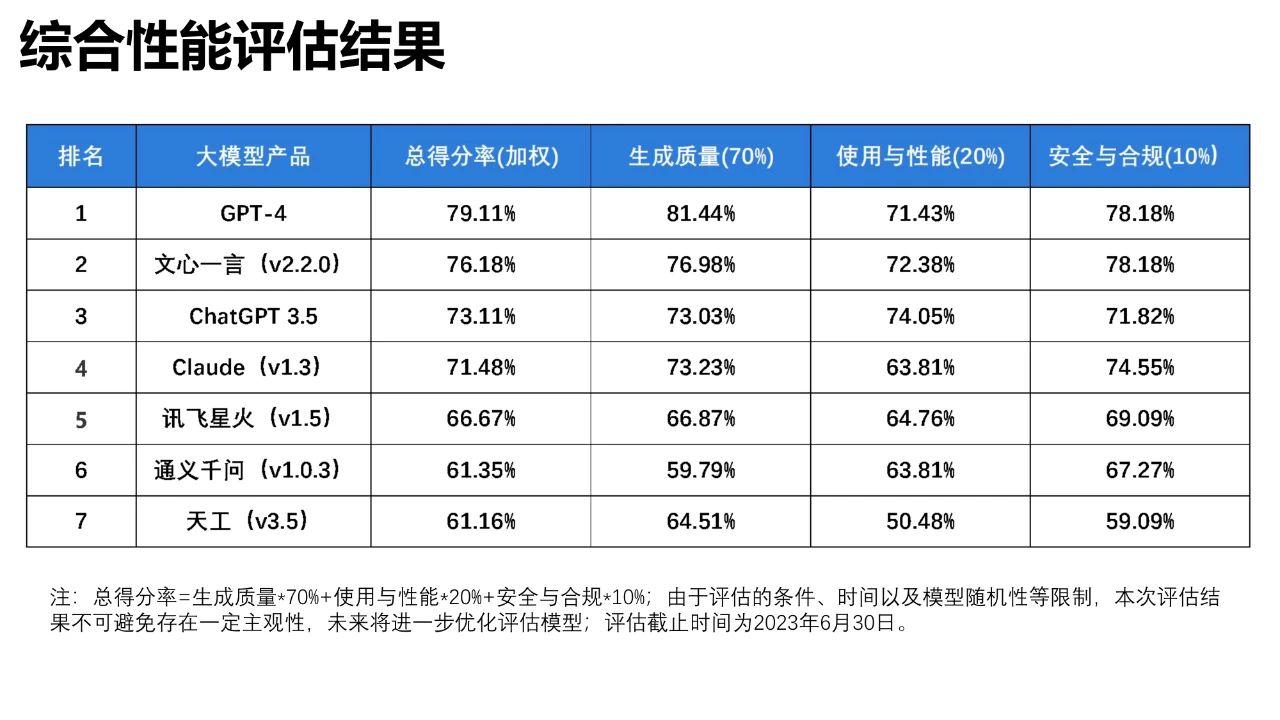
巴比特讯,据公众号“清元宇宙”,清华大学沈阳教授团队近日发布了《大语言模型综合性能评估报告》,报告从生成质量、使用与性能、安全与合规三个维度对大语言模型进行评估,并深入分析不同大语言模型之间的优劣。该报告总共对文心一言、讯飞星火、通义千问、昆仑天工、GPT-4、ChatGPT 3.5 和 Claude 七个大语音模型进行了评估分析。据综合性能评估结果显示,GPT-4 排名第一,文心一言和 ChatGPT 3.5 分别排名第二三位,阿里云通义千问则排在第六位。
此外,报告还针对大语言模型未来发展提出了强化跨语言迁移学习、扩大训练数据的范围、加强利用人工数据、推进敏感和有害信息的精准化过滤、理解社会影响和伦理限制等建议。

本文链接:https://www.8btc.com/article/6828792
转载请注明文章出处
原创文章,作者:惊蛰财经,如若转载,请注明出处:http://www.xmlm.net/bhq/25829.html
赞 (0)
联想浏览器推出小乐 AI 助手,实测已接入百度文心一言大模型
« 上一篇
2023年8月7日 pm10:52
微软 Windows 停止支持 Cortana 并专注于生成式 AI
下一篇 »
2023年8月7日 pm11:01